[Regarding the HGST 1TB drive]So, with no further insight, I did what my intuition told me : I attempted to overwrite just the tiny unreadable area with this
ddrescue command (could be done with the more basic
dd command but I'm less familiar with it) :
Code:
lubuntu@lubuntu:~$ sudo ddrescue -o 312881152 -s 53248 -f /dev/zero /dev/sdb /media/lubuntu/354E48E260FCFD84/dev_zero_dev_sdb.log
GNU ddrescue 1.22
ipos: 0 B, non-trimmed: 0 B, current rate: 53248 B/s
opos: 312881 kB, non-scraped: 0 B, average rate: 53248 B/s
non-tried: 0 B, bad-sector: 0 B, error rate: 0 B/s
rescued: 53248 B, bad areas: 0, run time: 0s
pct rescued: 100.00%, read errors: 0, remaining time: n/a
time since last successful read: n/a
Finished
[Note : the -f switch is necessary here since there is natively a protection preventing ddrescue from writing directly to a physical device.]And it worked : to verify I re-imaged the first GB and this time there was no error (I had tried this partial imaging before running the above command and the error area was still there then, with the exact same location and size, I also noticed that it was skipped right away, with no slowdown, contrary to what usually happens when there's an actual “physical” bad sector and it slows down or hangs for a few seconds before skipping) ; the “short self-test” now completes with no error as well.
Code:
lubuntu@lubuntu:~$ sudo ddrescue -S -P -v -s 1073741824 /dev/sdb /media/lubuntu/354E48E260FCFD84/HGST_HTS541010A9E680_JD1092DP1M6WAU_1G_2.dd /media/lubuntu/354E48E260FCFD84/HGST_HTS541010A9E680_JD1092DP1M6WAU_1G_2.log
GNU ddrescue 1.22
About to copy 1073 MBytes from '/dev/sdb' to '/media/lubuntu/354E48E260FCFD84/HGST_HTS541010A9E680_JD1092DP1M6WAU_1G_2.dd'
Starting positions: infile = 0 B, outfile = 0 B
Copy block size: 128 sectors Initial skip size: 19584 sectors
Sector size: 512 Bytes
Data preview:to interrupt
003FFF0000 1C 00 27 A7 EB DA 6D F3 EE D3 4E 12 FC 5C 57 B5 ..'...m...N..\W.
003FFF0010 CF 44 FA 31 7E 7F A3 8F 80 5F B1 AA 7D A1 9F 4F .D.1~...._..}..O
003FFF0020 BE DA D6 AD 9C 7E FB E7 CE 0B 69 55 5F 0F 03 06 .....~....iU_...
ipos: 1073 MB, non-trimmed: 0 B, current rate: 11730 kB/s
opos: 1073 MB, non-scraped: 0 B, average rate: 59652 kB/s
non-tried: 0 B, bad-sector: 0 B, error rate: 0 B/s
rescued: 1073 MB, bad areas: 0, run time: 17s
pct rescued: 100.00%, read errors: 0, remaining time: n/a
time since last successful read: n/a
Finished
Attachment:
 2018-07-10-040019_750x803_scrot.png [ 93.19 KiB | Viewed 13597 times ]
2018-07-10-040019_750x803_scrot.png [ 93.19 KiB | Viewed 13597 times ]
Before that I tried some Windows tools : a read scan with Hard Disk Sentinel made it freeze indefinitely, I had to shut down the drive ; likewise, trying to access the problematic area with WinHex made it freeze until the drive was shut down.
So, am I correct that this was a case of “logical” bad sectors, and that the drive is physically fine, and safe to use again ? What is the likely cause of this, perhaps a write operation interrupted by an improper shutdown ? Is this a common issue, and does it commonly render the drive inoperant, when it affects a system file ?
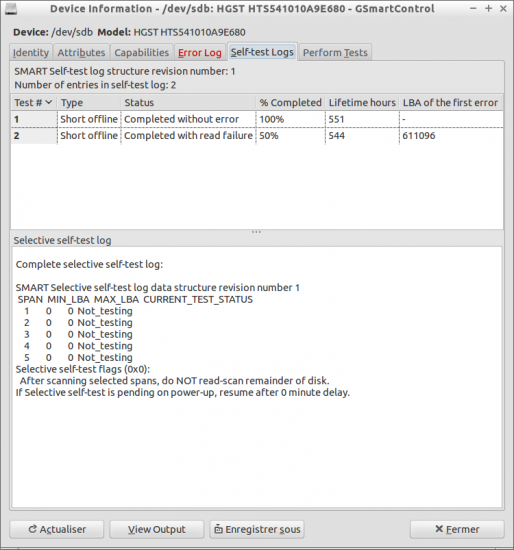
Regarding ddr_utilities, I tried again after starting fresh from the same live USB drive (actually a SD card connected through a USB reader) and it worked. Previously, I had downloaded ddrutilities-2.8.tar.gz, extracted it and installed it following the included manual, not knowing that it was pre-installed on this ISO, maybe there was a version conflict or something. And according to the analysis from ddru_findbad all the formerly unreadable sectors belonged to the same “/.journal” file :
Code:
Partition /dev/loop1p2 Type HFS DeviceSector 611096 PartitionSector 201456 Block 25182 Allocated yes Inode 16 File /.journal
...
Partition /dev/loop1p2 Type HFS DeviceSector 611199 PartitionSector 201559 Block 25194 Allocated yes Inode 16 File /.journal
Code:
########## ddru_findbad 1.11 20141015 summary output file ##########
There are 104 bad sectors total from the log file
104 sectors were in partitions that were able to be processed
104 sectors are listed as allocated
104 of those have a file or data listing related to them
leaving 0 that do not have a file or data listing related to them
0 sectors are listed as not allocated
...................................................................
Below is the list of files related to the bad sectors
with the number of bad sectors in each file
...................................................................
BadSectors=104 Inode 16 File /.journal
I guess that this is roughly equivalent to the $LogFile and $UsnJrnl files in NTFS. Could someone please elaborate ? Does the owner have to run some integrity check procedure to use the drive safely, and how is it called in MacOS ? (Again, I have very little experience with anything from Apple computers.)
[Regarding the Seagate drive]Quote:
Maybe you did a read/verify and some bad blocks were added as "pending". Then you did a zero fill or write to those sectors and the sectors were found to be good and removed from pending list but they do still cound as a Reallocation Event. "Maybe" those sectors that are now considered good were marked / counted on attribute 240 as Write Head.
Normally attributes are "standard" even if not implemented exactly the same way. Standards are not allways implemented as "expected" so different brands might have different responses even to standard commands ... Example are some drives/brands that will add sectors to G-List on READ/Verify attempts, etc ...
No, I imaged the drive right away, didn't write anything on it, and at no point there was anything but “0” in the “Pending Sector Count” field.
From what I understand, a reallocation event is just that,
as the name implies, when a sector gets actually reallocated, i.e. moved to G-list, not when it's counted as “pending” then cleared again – right ?
What exactly is “Write Head”, and how come the same SMART attribute code can refer to two distinct notions ? As “maximus” said, these values are vendor specific, so does anyone have a specific experience with that model or that range of models, and a definite knowledge of what those values mean here ? Again, can I confidently tell the owner that the drive is safe to use ? (Well, except for the fact that it's a Seagate, alright...)


